Kapitel 3 Erste Schritte mit R
Anhand einer Beispielsession möchte ich in das Arbeiten mit R/Rstudio einführen. Ich werde die relevanten Sprachkonzepte (die Grammatik) einführen, ein paar relevante Kommandos vorstellen (Vokabeln) und daneben auch etwas zur Motivation und Interpretation sagen.
3.1 Laden von Daten
Grundsätzlich kann man in R Daten in allen denkbaren Formaten importieren (dbase, shapefile, geopacke, geotiff, Posegresql Datenbanken, xls, xlsx, ods,…). Das gebräuchliste Format für tabellarische Daten sind CSV (comma separated values) Dateien, die jedoch in vielen Varianten vorkommen: unterschiedliche Trennzeichen, unterschiedliches Dezimaltrennzeichen, Kommentare, Spaltennamen in der ersten Zeile oder ohne Spaltennamen… read.table ist die Funktion um diese Daten einzulesen. Die Funktion benötigt den Dateinamen inklusive relativem oder absolutem Pfad sowie nähere Informationen zur Struktur der Daten.
Um sicher zu gehen, welche Struktur die Daten haben, sollte man sie einfach in einem Texteditor öffnen.
Wir laden hier die Datei temperatur.csv, die sich im Unterordner data befindet und zwar im aktuellem Arbeitsverzeichnis (RStudio Projektordner).
Also z.B. bei folgender Situation in ihrem Dateisystem (falls das Projektverzeichnis als C:/users/sn312/Documents/statistik/ definiert wurde):
C:/
├── users/
├──── sn312/
├────── Documents/
├──────── statistik/
├────────── data/
├──────────── temperature.csv
├──────────── niederschlag.csv
├──────── statistik.Rporj
├──────── u1.Rmdoder für folgende Situation auf einem Linux/Unix basiertem Dateisystem (falls das Projektverzeichnis als /users/sn312/home/Documents/statistik_vorlesung/ definiert wurde)
/
├── users/
├──── sn312/
├────── home/
├──────── Documents/
├────────── statistik_vorlesung/
├────────── data/
├──────────── temperature.csv
├──────────── niederschlag.csv
├──────── statistik.Rporj
├──────── u1.RmdWichtig: als Dateipfadtrennzeichen müssen Sie in R immer den Slash “/” verwenden, nicht den Backslash “\”, auch wenn der unter Windows gebräuchlich ist.7
Der Dateinamen muss als String (Zeichenkette) angegeben werden - d.h. er muss in doppelten oder einfachen Anführungszeichen stehen. Eine Zeichenkette, die nicht in Anführungszeichen eingeschlossen ist wird als Variablenname interpretiert. file="data/temperature.csv" ist ein korrekter Parameter zum Laden der Datei mit dem angegebenen Namen - falls die benannte Datei an der angegebenen Stelle existiert. Genauso korrekt wäre die Verwendung einfacher Anführungszeichen: file='data/temperature.csv'. Wichtig ist, dass einen Zeichenkette, die mit einfachen Anführungszeichen begonnen wird auch mit einfachem Anführungszeichen beendet wird - das gleiche gilt für doppelte Anführungszeichen.8 Falsch wäre ein Parameter der Form file=data/temperature.csv (ohne Anführungszeichen).
Weiterhin geben wir an, dass die erste Zeile die Spaltennamen enthält: header = TRUE. TRUE und FALSE sind dabei in R definierte Werte für wahr und falsch. Sie müssen in Großbuchstaben geschrieben werden.
Wenn wir - wie hier keine Trennzeichen definieren, wird Whitespace (Leerzeichen und Tabulatoren) als Trennzeichen interpretiert. Falls das Semikolon als Trennzeichen verwendet werden würde, müssten wir das wie folgt spezifizieren: sep=";". Die doppelten Anführungszeichen definieren dabei eine Zeichenkette (String).9
Funktionsaufrufe werden durch Parameter spezifiziert, die innerhalb von Klammern “()” spezifiziert werden. Die einzelnen Argumente werden dabei durch Kommas getrennt. Die Argumente können benannt sein (wie oben) oder nicht. Bei nicht benannten Parametern erfolgt die Zuordnung zu den Argumenten anhand der Position. Falls man die vielen Parameter eine Funktion nicht mehr weiß, kann man immer mittels help(funktionsname) oder ?funktionsname nachschauen.
read.table(file = "data/temperatur.csv", header = TRUE) und read.table("data/temperatur.csv", header = TRUE) sind gleichwertig, da file das erste Argument von read.table ist.
Die meisten Funktionen liefern einen Rückgabewert zurück, read.table liefert einen sogenannten data.frame zurück. Dies ist eine Art Tabellenobjekt, welches wir für Folgeoperationen wie Plotten, Regressionsmodelle,… verwenden. Deswegen wollen wir diese Rückgabeobjekt üblicherweise in einer Variablen speichern: temp <- read.table(file = "data/temperatur.csv", header = TRUE). Anschließend können wir mit datweiterarbeiten. <- ist ein Zuweisungsoperator: das Ergebnis der Funktion zur rechten des Operators wird der Variablen zur linken zugeordent.
Im Gegensatz zu vordefinierten Funktionen in R10 können wir Variablen so benennen wie wir wollen, sofern wir bestimmte Regeln einhalten. So muss ein Variablenname mit einem Buchstaben beginnen und darf dann aus weiteren Buchstaben, Ziffern, Unterstrichen oder Punkten bestehen (keine Leezeichen oder Bindestricht). Wichtig ist, dass der Name keine existierende R Funktion überschreibt11 und man mit dem Namen etwas anfangen kann. Im Beispiel handelt es sich um einen weltweiten Datensatz zu Temperaturmessstationen, deswegen schien mir temp sinnvoll, aber wir könnten die Variable auch Hans oder Adelheid nennen, wenn uns das sinnvoll erschiene.
Es empfiehlt sich generell, sich anzuschauen, was in dem Datensatz enthalten ist. Mit head(namedf) erhalten wir die ersten 6 Zeilen:
## TEMP_STA_1 FID_1 AREA PERIMETER TEMP_STATI COUNTRY_ID NAME LAT
## 1 100100 4752 0 0 4753 601 JAN MAYEN 70.93
## 2 100500 4753 0 0 4754 601 ISFJORD RADIO 78.07
## 3 100800 4754 0 0 4755 601 SVALBARD LUFTHAVN 78.25
## 4 101000 4755 0 0 4756 601 ANDOYA 69.30
## 5 102300 4756 0 0 4757 601 BARDUFOSS 69.05
## 6 102500 4757 0 0 4758 601 TROMSO/LANGNES 69.68
## LON ELEV FIRST LAST MISSING DISC FID_2 ISO_3DIGIT ISO_NUM CNTRY_NAME
## 1 -8.67 10 1921 1990 2.0 0 NA <NA> NA <NA>
## 2 13.63 5 1912 1979 15.1 0 NA <NA> NA <NA>
## 3 15.47 -999 1977 1990 8.9 0 NA <NA> NA <NA>
## 4 16.15 -999 1981 1990 1.7 0 NA <NA> NA <NA>
## 5 18.55 -999 1981 1990 1.7 0 102 NOR 578 Norway
## 6 18.92 -999 1856 1990 29.4 0 NA <NA> NA <NA>
## LONG_NAME SQKM SQMI centerX centerY JAN FEB MAR
## 1 <NA> NA NA NA NA -4.406 -4.983 -5.096
## 2 <NA> NA NA NA NA -12.302 -13.359 -14.429
## 3 <NA> NA NA NA NA -15.569 -15.187 -14.225
## 4 <NA> NA NA NA NA -2.390 -1.800 -1.490
## 5 Kingdom of Norway 305865.7 118094.8 14.0848 64.44817 -10.760 -8.110 -5.440
## 6 <NA> NA NA NA NA -3.301 -3.619 -2.658
## APR MAI JUN JUL AUG SEP OCT NOV DEC YEAR
## 1 -3.403 -0.497 2.303 4.789 5.321 3.313 0.401 -1.985 -3.822 -0.672083
## 2 -10.739 -3.678 1.857 5.122 4.563 0.796 -4.200 -8.219 -10.502 -5.424170
## 3 -11.519 -3.631 2.187 6.120 4.975 0.488 -5.747 -9.687 -13.356 -6.262580
## 4 0.950 5.140 8.070 10.820 10.620 7.630 4.490 0.644 -2.133 3.379250
## 5 -0.280 5.460 9.620 12.670 10.760 6.270 1.610 -5.900 -10.333 0.463917
## 6 0.334 4.243 8.717 11.698 10.728 7.044 2.662 -0.656 -2.459 2.727750Mit names(namedf) die Spaltennamen:
## [1] "TEMP_STA_1" "FID_1" "AREA" "PERIMETER" "TEMP_STATI"
## [6] "COUNTRY_ID" "NAME" "LAT" "LON" "ELEV"
## [11] "FIRST" "LAST" "MISSING" "DISC" "FID_2"
## [16] "ISO_3DIGIT" "ISO_NUM" "CNTRY_NAME" "LONG_NAME" "SQKM"
## [21] "SQMI" "centerX" "centerY" "JAN" "FEB"
## [26] "MAR" "APR" "MAI" "JUN" "JUL"
## [31] "AUG" "SEP" "OCT" "NOV" "DEC"
## [36] "YEAR"Was die Spaltennamen bedeuten, müssen Sie den - hoffentlich mitgelieferten - Metadaten entnehmen. Der Datensatz enthält weltweit Temperaturmeßstationen zusammen mit der Höhe der Meßstation (müNN), der Breiten und Längen der Station (LAT, LON), dem Ländernamen “CNTRY_NAME” sowie dem langjährigen Mittelwert der Jahrestemperatur (YEAR) sdowie der Monatsmitteltemperatur. Alle anderen Werte wollen wir hier ignorieren.
Mit summary(namedf) erhalten wir eine Übersicht über die Verteilung der Werte:
## TEMP_STA_1 FID_1 AREA PERIMETER TEMP_STATI
## Min. : 100100 Min. : 0 Min. :0 Min. :0 Min. : 1
## 1st Qu.:3171600 1st Qu.:1510 1st Qu.:0 1st Qu.:0 1st Qu.:1510
## Median :6450000 Median :3019 Median :0 Median :0 Median :3020
## Mean :5460681 Mean :3019 Mean :0 Mean :0 Mean :3020
## 3rd Qu.:7257246 3rd Qu.:4528 3rd Qu.:0 3rd Qu.:0 3rd Qu.:4530
## Max. :9909001 Max. :6038 Max. :0 Max. :0 Max. :6039
##
## COUNTRY_ID NAME LAT LON
## Min. :101.0 Length:6039 Min. :-90.00 Min. :-179.980
## 1st Qu.:229.0 Class :character 1st Qu.: 23.02 1st Qu.: -85.930
## Median :404.0 Mode :character Median : 39.15 Median : 6.530
## Mean :382.9 Mean : 31.95 Mean : -3.977
## 3rd Qu.:513.0 3rd Qu.: 47.93 3rd Qu.: 69.405
## Max. :799.0 Max. : 82.50 Max. : 179.750
##
## ELEV FIRST LAST MISSING
## Min. :-999.00 Min. :1701 Min. :1910 Min. : 0.000
## 1st Qu.: 2.00 1st Qu.:1900 1st Qu.:1987 1st Qu.: 1.700
## Median : 65.00 Median :1951 Median :1990 Median : 3.300
## Mean : 67.96 Mean :1936 Mean :1986 Mean : 8.702
## 3rd Qu.: 366.00 3rd Qu.:1981 3rd Qu.:1990 3rd Qu.: 9.200
## Max. :3832.00 Max. :1981 Max. :1990 Max. :78.500
##
## DISC FID_2 ISO_3DIGIT ISO_NUM
## Min. :0.00000 Min. : 0.0 Length:6039 Min. : 0.0
## 1st Qu.:0.00000 1st Qu.:103.0 Class :character 1st Qu.:214.0
## Median :0.00000 Median :153.0 Mode :character Median :642.0
## Mean :0.01523 Mean :131.5 Mean :524.1
## 3rd Qu.:0.00000 3rd Qu.:154.0 3rd Qu.:840.0
## Max. :1.00000 Max. :247.0 Max. :894.0
## NA's :566 NA's :566
## CNTRY_NAME LONG_NAME SQKM SQMI
## Length:6039 Length:6039 Min. :3.800e+00 Min. : 1.5
## Class :character Class :character 1st Qu.:4.466e+05 1st Qu.: 172445.0
## Mode :character Mode :character Median :9.403e+06 Median :3630454.7
## Mean :6.104e+06 Mean :2356783.2
## 3rd Qu.:9.426e+06 3rd Qu.:3639492.5
## Max. :1.690e+07 Max. :6524043.5
## NA's :566 NA's :566
## centerX centerY JAN FEB
## Min. :-177.379 Min. :-80.45 Min. :-47.705 Min. :-44.330
## 1st Qu.:-112.492 1st Qu.: 27.04 1st Qu.: -6.146 1st Qu.: -4.769
## Median : 5.603 Median : 45.70 Median : 1.733 Median : 3.043
## Mean : -8.682 Mean : 35.74 Mean : 3.205 Mean : 4.479
## 3rd Qu.: 96.578 3rd Qu.: 46.84 3rd Qu.: 15.015 3rd Qu.: 15.934
## Max. : 178.557 Max. : 78.86 Max. : 32.678 Max. : 31.589
## NA's :566 NA's :566
## MAR APR MAI JUN
## Min. :-57.9570 Min. :-64.757 Min. :-65.64 Min. :-65.25
## 1st Qu.: -0.1325 1st Qu.: 6.069 1st Qu.: 11.34 1st Qu.: 14.95
## Median : 6.4890 Median : 11.262 Median : 15.67 Median : 19.21
## Mean : 7.9566 Mean : 12.231 Mean : 16.12 Mean : 19.12
## 3rd Qu.: 17.9535 3rd Qu.: 19.116 3rd Qu.: 21.57 3rd Qu.: 24.40
## Max. : 32.3880 Max. : 34.123 Max. : 35.76 Max. : 36.94
##
## JUL AUG SEP OCT
## Min. :-66.92 Min. :-67.66 Min. :-66.01 Min. :-57.172
## 1st Qu.: 17.25 1st Qu.: 16.45 1st Qu.: 12.85 1st Qu.: 7.867
## Median : 21.58 Median : 20.90 Median : 17.53 Median : 12.570
## Mean : 20.91 Mean : 20.40 Mean : 17.56 Mean : 13.451
## 3rd Qu.: 25.79 3rd Qu.: 25.57 3rd Qu.: 23.48 3rd Qu.: 20.489
## Max. : 38.30 Max. : 37.01 Max. : 34.79 Max. : 32.470
##
## NOV DEC YEAR
## Min. :-43.3720 Min. :-45.784 Min. :-55.280
## 1st Qu.: 0.9895 1st Qu.: -3.975 1st Qu.: 6.478
## Median : 6.8670 Median : 3.258 Median : 11.505
## Mean : 8.3392 Mean : 4.605 Mean : 12.365
## 3rd Qu.: 17.9685 3rd Qu.: 15.650 3rd Qu.: 19.316
## Max. : 33.2450 Max. : 32.855 Max. : 31.108
## Wir können über den Dollaroperator “$” auf einzelne Spalten zugreifen. Die Spalte wird dann als ein Vektor zurückgegeben.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -999.00 2.00 65.00 67.96 366.00 3832.00Wollen wir wissen, welche verschiedenen Ländernamen es in dem Datensatz gibt, können wir die Funktion unique anwenden:
## [1] NA
## [2] "Norway"
## [3] "Svalbard"
## [4] "Sweden"
## [5] "Finland"
## [6] "United Kingdom"
## [7] "Isle of Man"
## [8] "Guernsey"
## [9] "Jersey"
## [10] "Ireland"
## [11] "Iceland"
## [12] "Greenland"
## [13] "Faroe Is."
## [14] "Denmark"
## [15] "Netherlands"
## [16] "Belgium"
## [17] "Luxembourg"
## [18] "Switzerland"
## [19] "Germany"
## [20] "Liechtenstein"
## [21] "France"
## [22] "Spain"
## [23] "Portugal"
## [24] "Cape Verde"
## [25] "Czech Republic"
## [26] "Austria"
## [27] "Slovakia"
## [28] "Poland"
## [29] "Hungary"
## [30] "Slovenia"
## [31] "Serbia & Montenegro"
## [32] "Croatia"
## [33] "Bosnia & Herzegovina"
## [34] "Macedonia"
## [35] "Albania"
## [36] "Ukraine"
## [37] "Romania"
## [38] "Bulgaria"
## [39] "Italy"
## [40] "Malta"
## [41] "Greece"
## [42] "Turkey"
## [43] "Cyprus"
## [44] "Russia"
## [45] "Estonia"
## [46] "Latvia"
## [47] "Lithuania"
## [48] "Belarus"
## [49] "Kazakhstan"
## [50] "Moldova"
## [51] "Kyrgyzstan"
## [52] "Georgia"
## [53] "Azerbaijan"
## [54] "Armenia"
## [55] "Uzbekistan"
## [56] "Turkmenistan"
## [57] "Tajikistan"
## [58] "Syria"
## [59] "Lebanon"
## [60] "Israel"
## [61] "West Bank"
## [62] "Jordan"
## [63] "Saudi Arabia"
## [64] "Kuwait"
## [65] "Iraq"
## [66] "Iran"
## [67] "Afghanistan"
## [68] "Bahrain"
## [69] "Qatar"
## [70] "United Arab Emirates"
## [71] "Oman"
## [72] "Yemen"
## [73] "Pakistan"
## [74] "Bangladesh"
## [75] "India"
## [76] "Sri Lanka"
## [77] "Mongolia"
## [78] "Nepal"
## [79] "China"
## [80] "North Korea"
## [81] "South Korea"
## [82] "Japan"
## [83] "Myanmar"
## [84] "Thailand"
## [85] "Malaysia"
## [86] "Singapore"
## [87] "Vietnam"
## [88] "Laos"
## [89] "Cambodia"
## [90] "Morocco"
## [91] "Algeria"
## [92] "Tunisia"
## [93] "Niger"
## [94] "Mali"
## [95] "Mauritania"
## [96] "Senegal"
## [97] "The Gambia"
## [98] "Guinea-Bissau"
## [99] "Guinea"
## [100] "Sierra Leone"
## [101] "St. Helena"
## [102] "Sao Tome & Principe"
## [103] "British Indian Ocean Territory"
## [104] "Reunion"
## [105] "Mauritius"
## [106] "French Southern & Antarctic Lands"
## [107] "Libya"
## [108] "Egypt"
## [109] "Gaza Strip"
## [110] "Sudan"
## [111] "Eritrea"
## [112] "Djibouti"
## [113] "Somalia"
## [114] "Ethiopia"
## [115] "Kenya"
## [116] "Uganda"
## [117] "Tanzania"
## [118] "Congo, DRC"
## [119] "Burundi"
## [120] "Congo"
## [121] "Gabon"
## [122] "Central African Republic"
## [123] "Chad"
## [124] "Cameroon"
## [125] "Nigeria"
## [126] "Benin"
## [127] "Togo"
## [128] "Ghana"
## [129] "Burkina Faso"
## [130] "Cote d'Ivoire"
## [131] "Liberia"
## [132] "Angola"
## [133] "Comoros"
## [134] "Mayotte"
## [135] "Madagascar"
## [136] "Mozambique"
## [137] "Malawi"
## [138] "Zambia"
## [139] "Zimbabwe"
## [140] "Namibia"
## [141] "Botswana"
## [142] "South Africa"
## [143] "United States"
## [144] "Canada"
## [145] "St. Pierre & Miquelon"
## [146] "Mexico"
## [147] "The Bahamas"
## [148] "Cuba"
## [149] "Jamaica"
## [150] "Haiti"
## [151] "Dominican Republic"
## [152] "Puerto Rico"
## [153] "Virgin Is."
## [154] "Belize"
## [155] "Guatemala"
## [156] "El Salvador"
## [157] "Honduras"
## [158] "Nicaragua"
## [159] "Costa Rica"
## [160] "Panama"
## [161] "St. Kitts & Nevis"
## [162] "Guadeloupe"
## [163] "Martinique"
## [164] "Barbados"
## [165] "Trinidad & Tobago"
## [166] "Netherlands Antilles"
## [167] "Colombia"
## [168] "Venezuela"
## [169] "Guyana"
## [170] "Suriname"
## [171] "French Guiana"
## [172] "Brazil"
## [173] "Ecuador"
## [174] "Peru"
## [175] "Bolivia"
## [176] "Argentina"
## [177] "Chile"
## [178] "Paraguay"
## [179] "Uruguay"
## [180] "Falkland Is."
## [181] "Antarctica"
## [182] "South Georgia & the South Sandwich Is."
## [183] "Midway Is."
## [184] "Guam"
## [185] "Northern Mariana Is."
## [186] "Micronesia"
## [187] "Marshall Is."
## [188] "Palau"
## [189] "Solomon Is."
## [190] "Vanuatu"
## [191] "New Caledonia"
## [192] "Tuvalu"
## [193] "Fiji"
## [194] "Wallis & Futuna"
## [195] "American Samoa"
## [196] "Tonga"
## [197] "Niue"
## [198] "Cook Is."
## [199] "French Polynesia"
## [200] "Pitcairn Is."
## [201] "New Zealand"
## [202] "Papua New Guinea"
## [203] "Australia"
## [204] "Norfolk I."
## [205] "Indonesia"
## [206] "Christmas I."
## [207] "Timor Leste"
## [208] "Philippines"Wollen wir die Namen sortiert haben, können wir sort auf das Ergebnis anwenden:
## [1] "Afghanistan"
## [2] "Albania"
## [3] "Algeria"
## [4] "American Samoa"
## [5] "Angola"
## [6] "Antarctica"
## [7] "Argentina"
## [8] "Armenia"
## [9] "Australia"
## [10] "Austria"
## [11] "Azerbaijan"
## [12] "Bahrain"
## [13] "Bangladesh"
## [14] "Barbados"
## [15] "Belarus"
## [16] "Belgium"
## [17] "Belize"
## [18] "Benin"
## [19] "Bolivia"
## [20] "Bosnia & Herzegovina"
## [21] "Botswana"
## [22] "Brazil"
## [23] "British Indian Ocean Territory"
## [24] "Bulgaria"
## [25] "Burkina Faso"
## [26] "Burundi"
## [27] "Cambodia"
## [28] "Cameroon"
## [29] "Canada"
## [30] "Cape Verde"
## [31] "Central African Republic"
## [32] "Chad"
## [33] "Chile"
## [34] "China"
## [35] "Christmas I."
## [36] "Colombia"
## [37] "Comoros"
## [38] "Congo"
## [39] "Congo, DRC"
## [40] "Cook Is."
## [41] "Costa Rica"
## [42] "Cote d'Ivoire"
## [43] "Croatia"
## [44] "Cuba"
## [45] "Cyprus"
## [46] "Czech Republic"
## [47] "Denmark"
## [48] "Djibouti"
## [49] "Dominican Republic"
## [50] "Ecuador"
## [51] "Egypt"
## [52] "El Salvador"
## [53] "Eritrea"
## [54] "Estonia"
## [55] "Ethiopia"
## [56] "Falkland Is."
## [57] "Faroe Is."
## [58] "Fiji"
## [59] "Finland"
## [60] "France"
## [61] "French Guiana"
## [62] "French Polynesia"
## [63] "French Southern & Antarctic Lands"
## [64] "Gabon"
## [65] "Gaza Strip"
## [66] "Georgia"
## [67] "Germany"
## [68] "Ghana"
## [69] "Greece"
## [70] "Greenland"
## [71] "Guadeloupe"
## [72] "Guam"
## [73] "Guatemala"
## [74] "Guernsey"
## [75] "Guinea"
## [76] "Guinea-Bissau"
## [77] "Guyana"
## [78] "Haiti"
## [79] "Honduras"
## [80] "Hungary"
## [81] "Iceland"
## [82] "India"
## [83] "Indonesia"
## [84] "Iran"
## [85] "Iraq"
## [86] "Ireland"
## [87] "Isle of Man"
## [88] "Israel"
## [89] "Italy"
## [90] "Jamaica"
## [91] "Japan"
## [92] "Jersey"
## [93] "Jordan"
## [94] "Kazakhstan"
## [95] "Kenya"
## [96] "Kuwait"
## [97] "Kyrgyzstan"
## [98] "Laos"
## [99] "Latvia"
## [100] "Lebanon"
## [101] "Liberia"
## [102] "Libya"
## [103] "Liechtenstein"
## [104] "Lithuania"
## [105] "Luxembourg"
## [106] "Macedonia"
## [107] "Madagascar"
## [108] "Malawi"
## [109] "Malaysia"
## [110] "Mali"
## [111] "Malta"
## [112] "Marshall Is."
## [113] "Martinique"
## [114] "Mauritania"
## [115] "Mauritius"
## [116] "Mayotte"
## [117] "Mexico"
## [118] "Micronesia"
## [119] "Midway Is."
## [120] "Moldova"
## [121] "Mongolia"
## [122] "Morocco"
## [123] "Mozambique"
## [124] "Myanmar"
## [125] "Namibia"
## [126] "Nepal"
## [127] "Netherlands"
## [128] "Netherlands Antilles"
## [129] "New Caledonia"
## [130] "New Zealand"
## [131] "Nicaragua"
## [132] "Niger"
## [133] "Nigeria"
## [134] "Niue"
## [135] "Norfolk I."
## [136] "North Korea"
## [137] "Northern Mariana Is."
## [138] "Norway"
## [139] "Oman"
## [140] "Pakistan"
## [141] "Palau"
## [142] "Panama"
## [143] "Papua New Guinea"
## [144] "Paraguay"
## [145] "Peru"
## [146] "Philippines"
## [147] "Pitcairn Is."
## [148] "Poland"
## [149] "Portugal"
## [150] "Puerto Rico"
## [151] "Qatar"
## [152] "Reunion"
## [153] "Romania"
## [154] "Russia"
## [155] "Sao Tome & Principe"
## [156] "Saudi Arabia"
## [157] "Senegal"
## [158] "Serbia & Montenegro"
## [159] "Sierra Leone"
## [160] "Singapore"
## [161] "Slovakia"
## [162] "Slovenia"
## [163] "Solomon Is."
## [164] "Somalia"
## [165] "South Africa"
## [166] "South Georgia & the South Sandwich Is."
## [167] "South Korea"
## [168] "Spain"
## [169] "Sri Lanka"
## [170] "St. Helena"
## [171] "St. Kitts & Nevis"
## [172] "St. Pierre & Miquelon"
## [173] "Sudan"
## [174] "Suriname"
## [175] "Svalbard"
## [176] "Sweden"
## [177] "Switzerland"
## [178] "Syria"
## [179] "Tajikistan"
## [180] "Tanzania"
## [181] "Thailand"
## [182] "The Bahamas"
## [183] "The Gambia"
## [184] "Timor Leste"
## [185] "Togo"
## [186] "Tonga"
## [187] "Trinidad & Tobago"
## [188] "Tunisia"
## [189] "Turkey"
## [190] "Turkmenistan"
## [191] "Tuvalu"
## [192] "Uganda"
## [193] "Ukraine"
## [194] "United Arab Emirates"
## [195] "United Kingdom"
## [196] "United States"
## [197] "Uruguay"
## [198] "Uzbekistan"
## [199] "Vanuatu"
## [200] "Venezuela"
## [201] "Vietnam"
## [202] "Virgin Is."
## [203] "Wallis & Futuna"
## [204] "West Bank"
## [205] "Yemen"
## [206] "Zambia"
## [207] "Zimbabwe"Das Verschachteln der Funktionen erhöht nicht unbedingt die Übersichtlichkeit, weswegen wir hier auch immer wieder den Pipe-Operator “%>%” verwenden werden. Hierfür muss jedoch zunächst ein Zusatzpaket installiert und geladen werden. Dazu später mehr, hier einfach nur die Syntax:
temp$CNTRY_NAME %>% unique() %>% sort()
Der Pipe-Operator übergibt einfach das Ergebnis der linken Funktion als erster Argument an die Funktion zur rechten.
3.2 Packages - Zusatzfunktionen
Es gibt hunderte von Zusatzpaketen (packages) für R, die weitere Funktionen nachrüsten. Einige sind bereits mit R installiert worden, andere müssen Sie nachinstallieren (Packages -> Install). Um installierte packages verfügbar zu machen, muss das package geladen werden: require(packagename)oder library(packagename).
Beim Pipe-Operator ist dies das package magrittr, das Teil eine Meta-packages tidyverse ist, dass wir gelegentlich laden werden.
3.3 Filtern
Wir möchten nun nur die Klimastationen eines einzelnen Landes auswählen. Hierzu verwenden wir den Befehl subset um eine logische Bedingung zu formulieren. Wichtig ist das doppelte Gleicheitszeichen. Während ein einfaches Gleichheitszeichen eine Zuweisung bedeutet, bedeutet ein doppletes Gleichheitszeichen einen logischen Vergleich. Subset liefert eine Teilmenge des data.frames zurück, die wir in einer neuen Variable speichern.
Mittels dim schauen wir uns an, wieviele Stationen wir damit erhalten haben.
## [1] 6039 36## [1] 16 363.4 Plotten mit ggplot2
Es gibt in R mindestens 3 große packages zum Plotten:
graphicslatticeggplot2
graphics ist etwas intuitiver, aber auch deutlich umständlicher bei etwas komplexeren Abbildungen. ggplot2 ist nicht ganz so intuitiv, aber sehr komfortabel. Wir wollen uns hier erstmal ggplot2 anschauen.
ggplot2` folgt folgender Logik:
ggplot()spezifiziert über den Parameterdata =den data.frame (tabellarischen Datensatz), aus dem die zu plottenden Daten stammen. Mittelmapping = aes()werden die Felder des data.frames auf graphische Variablen gematcht.- dann werden mittels (überladenem)
+Operator weitere Manipulationen vorgenommen. - relevant ist vor allem die Definition wie die Variablen dargestellt werden sollen. Für einen Scatterplot ist das
geom_point(), Linien kann man übergeom_line()darstellen, Histogramme übergeom_histogramm()und vieles viels mehr. - dann können z.B. die Achsenbeschriftungen überarbeitet werden, ein Titel vergeben werden, die Skalierung der Achsen geändert werden oder Text in der Abbildung platziert werden.
## Loading required package: ggplot2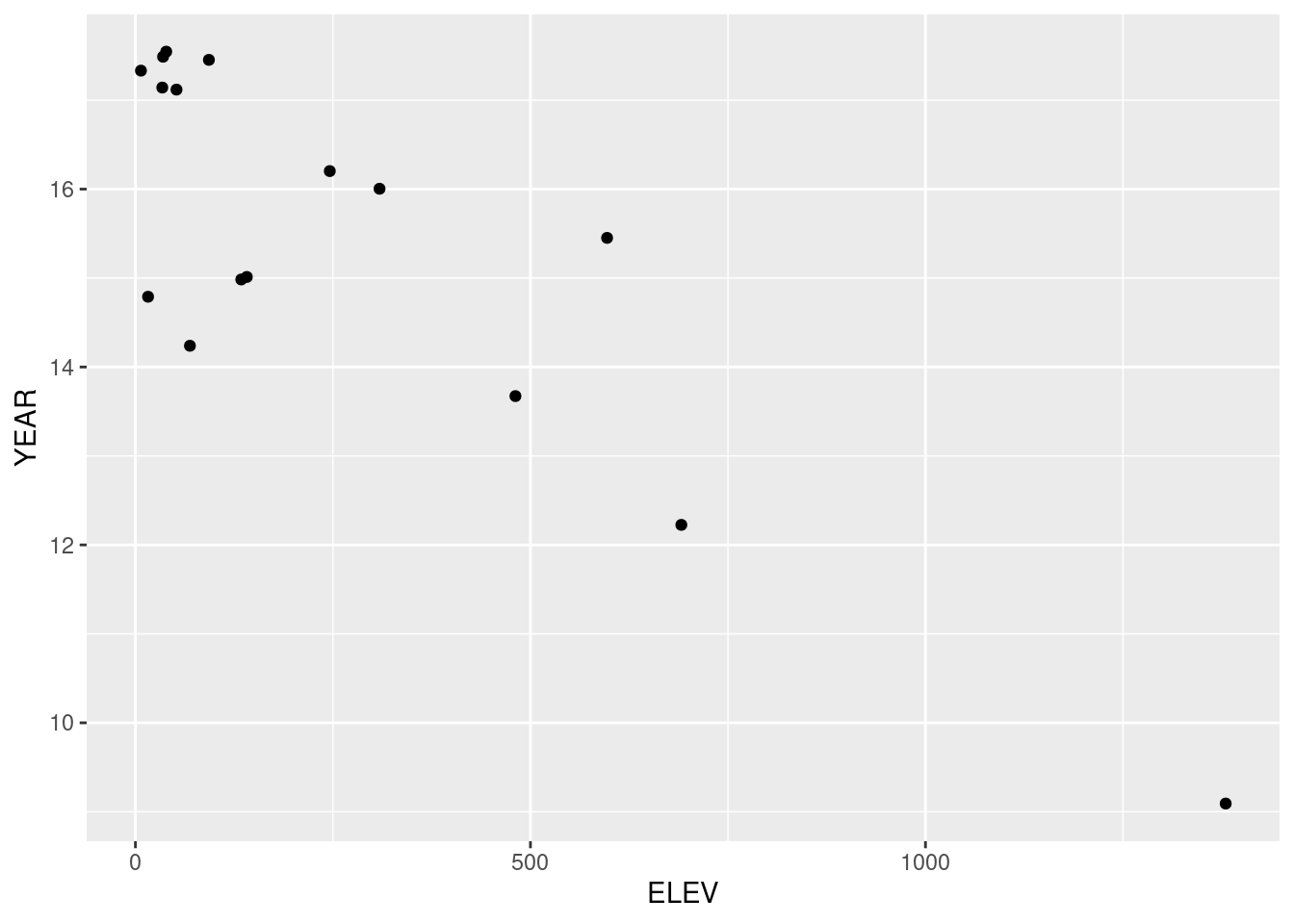
Etwas hübscher
ggplot(data= temp.pt, mapping = aes(x=ELEV, y= YEAR)) +
geom_point() +
xlab("Geländehöhe [müNN]") +
ylab("Mittlere Jahrestemperatur [°C]") +
labs(title = "Temperaturstationen Portugal")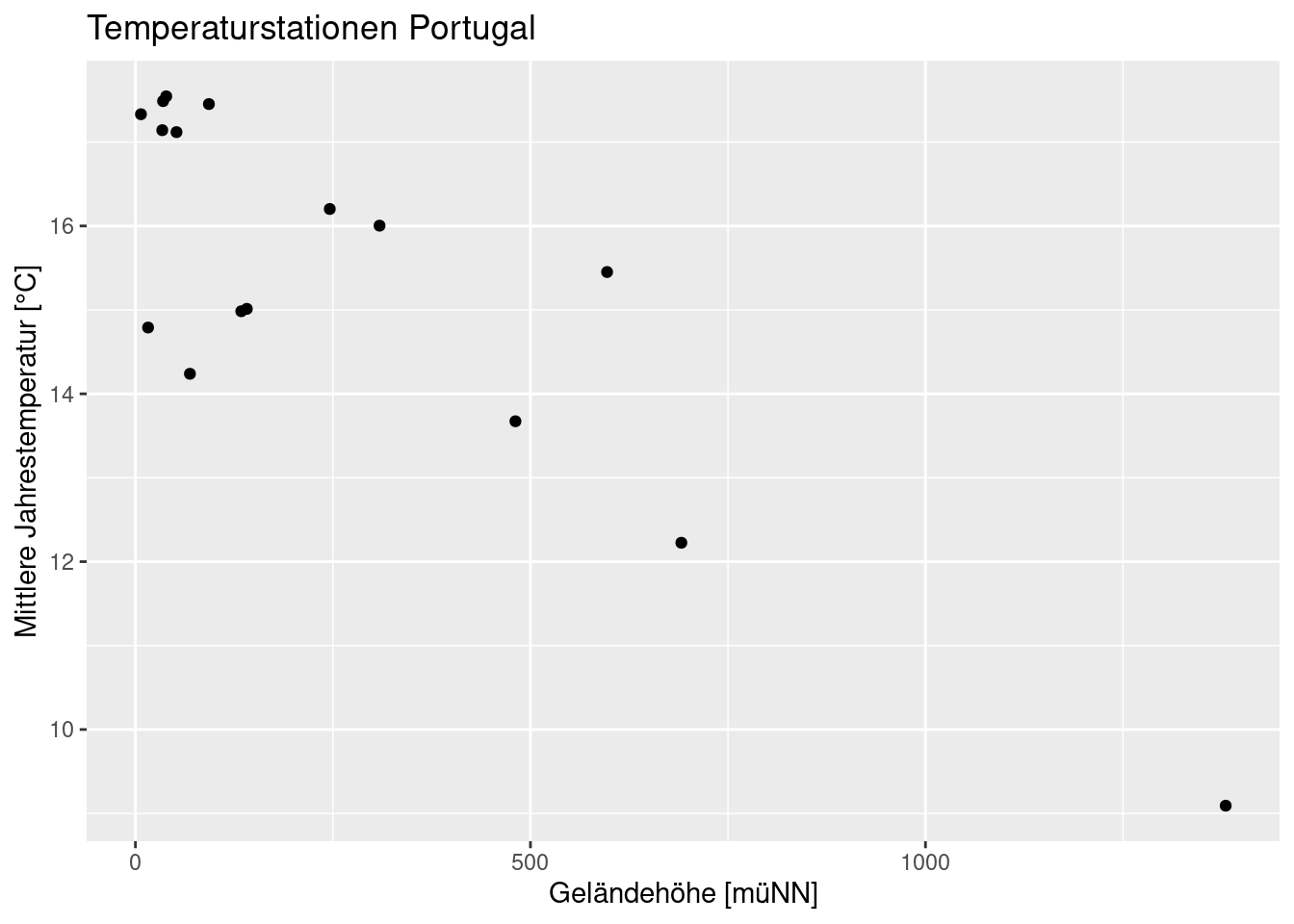
ggplot(data= temp.pt, mapping = aes(x=ELEV, y= YEAR)) +
geom_point(color = "red", alpha = 0.5) +
xlab("Geländehöhe [müNN]") +
ylab("Mittlere Jahrestemperatur [°C]") +
labs(title = "Temperaturstationen Portugal")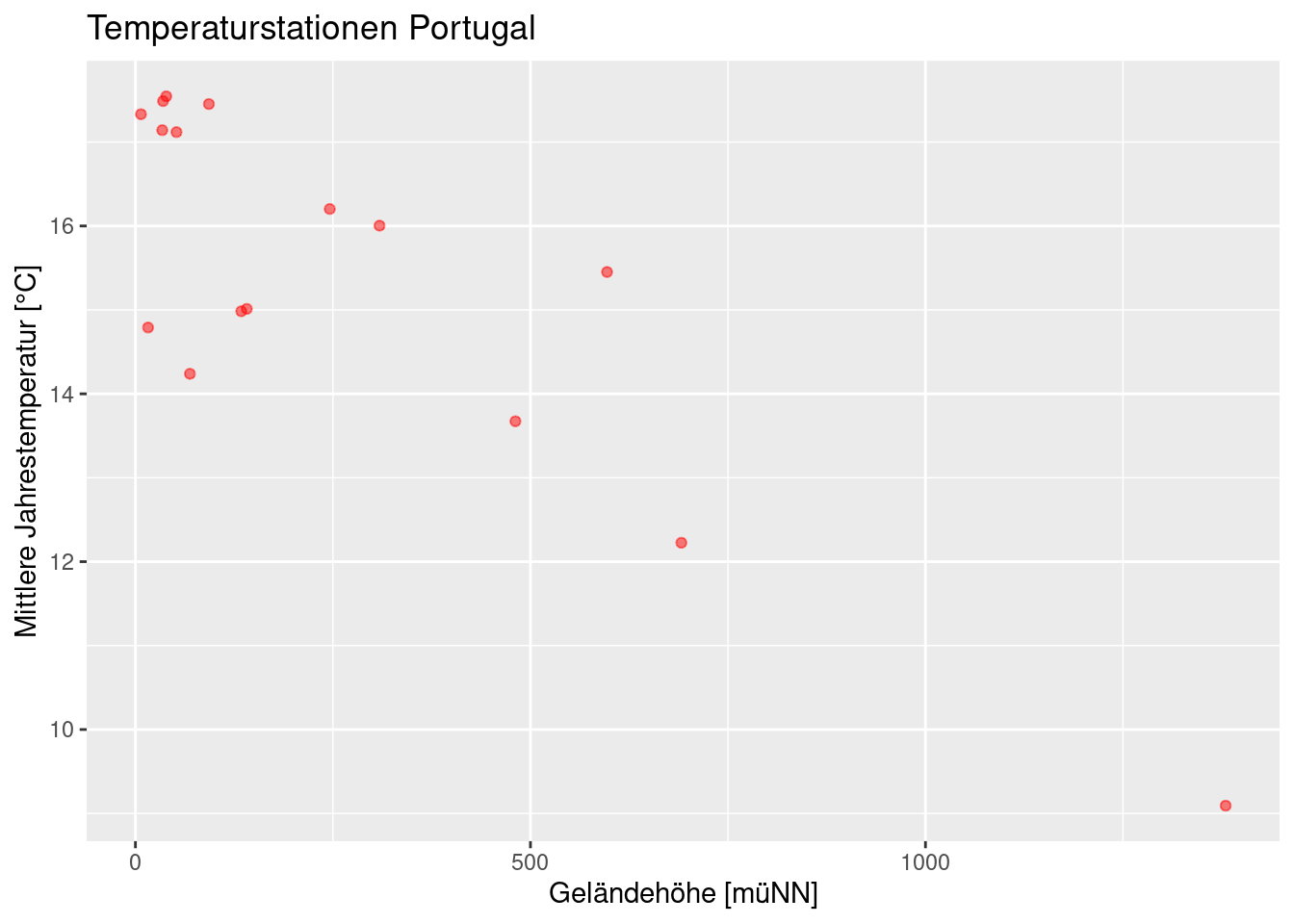
Die Flexibilität von ggplot2 wird klar, wenn wir mehr als ein Land plotten wollen. Wir können Farbe als weiter graphische Variable mappen:
temp.multi <- subset(temp, CNTRY_NAME %in% c("Portugal", "Spain", "France", "Italy"))
ggplot(data= temp.multi, mapping = aes(x=ELEV, y= YEAR, color = CNTRY_NAME)) +
geom_point(alpha = 0.5) +
xlab("Geländehöhe [müNN]") +
ylab("Mittlere Jahrestemperatur [°C]")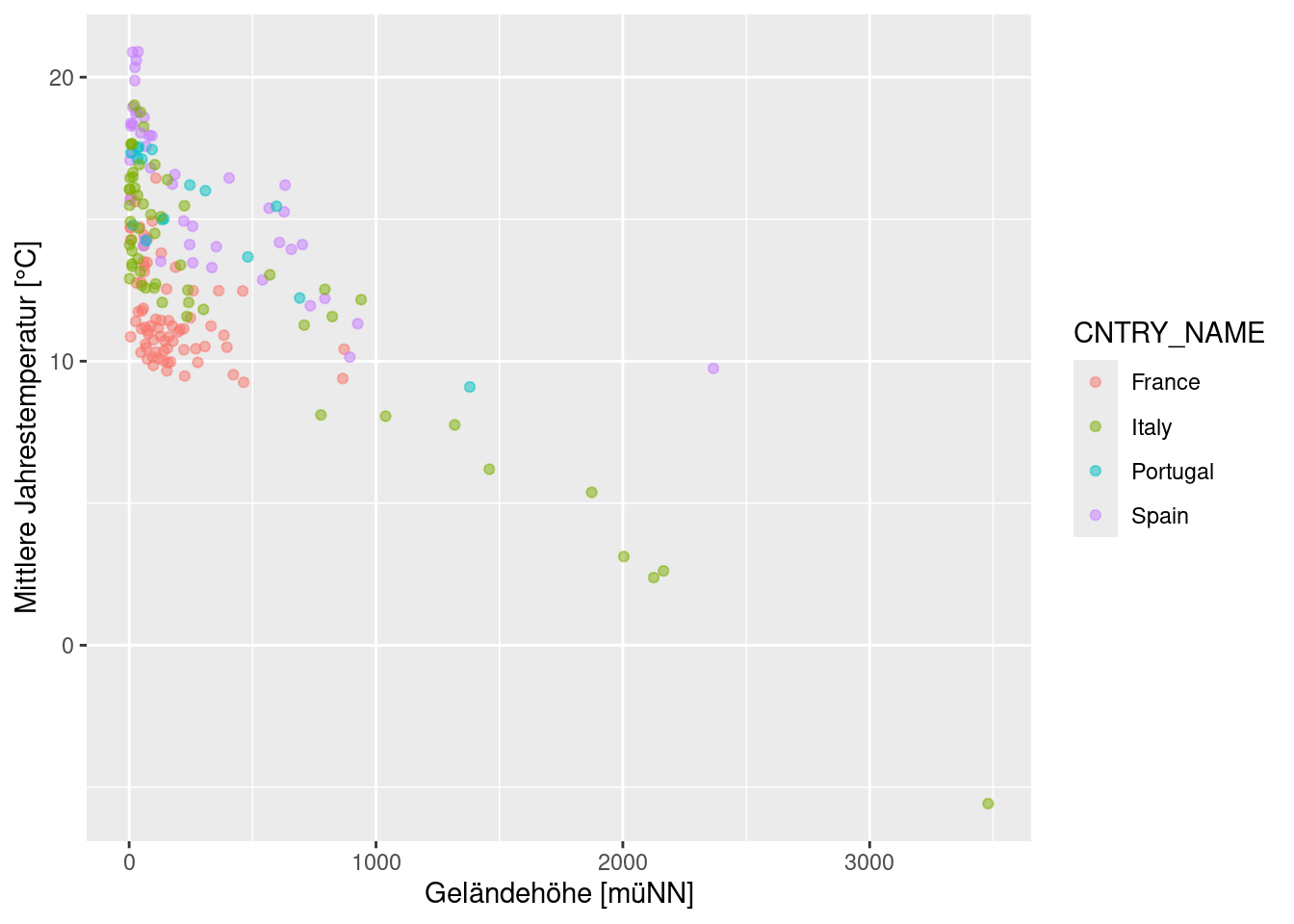
oder wir erzeugen mitteln facet_wrap einen Plot je Land (eindeutiger Variablenwert der in facet_wrap definierten Variable(n))
ggplot(data= temp.multi, mapping = aes(x=ELEV, y= YEAR)) +
geom_point(alpha = 0.5) +
facet_wrap(~ CNTRY_NAME) +
xlab("Geländehöhe [müNN]") +
ylab("Mittlere Jahrestemperatur [°C]")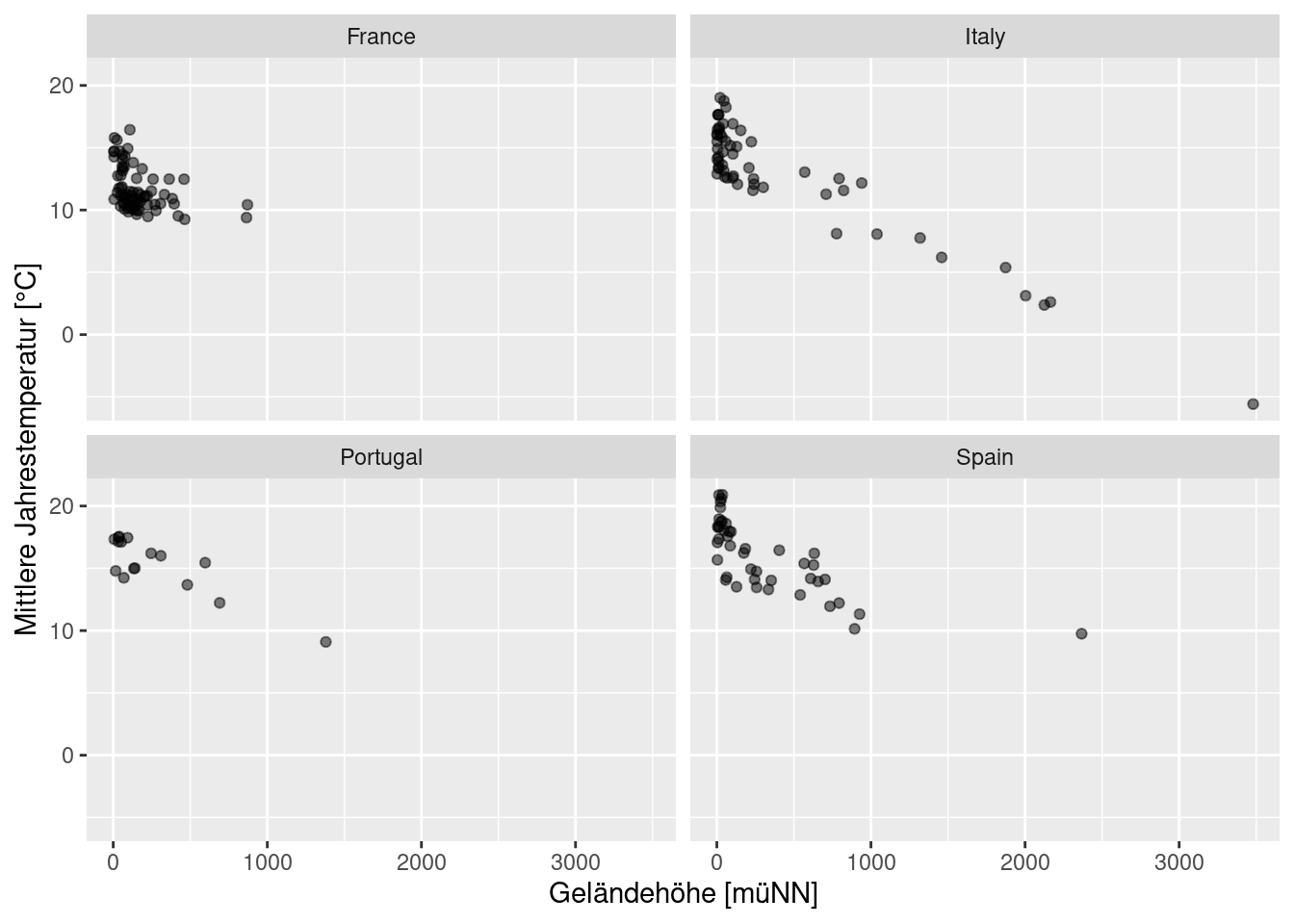
Ja, auch dann, wenn Sie unter Windows arbeiten.↩︎
Das ermöglicht es, Zeichenketten zu definieren, in denen einfache oder doppelte Anführungszeichen vorkommen, z.B. “Moran’s I ist ein gebräuchliches Maß um räumliche Autokorrelation zu beschreiben.”. In Dateinamen ist das nicht erlaubt.↩︎
Dadurch lassen sich auch längere Zeichenketten als Trennzeichen definieren. Ungewöhnlich, aber möglich.↩︎
wir können auch selbst Funktionen definieren.↩︎
kann man problemlos rückgängig machen↩︎