Tag 2 - Kontrollstrukturen und komplexe Datentypen#
Python-Skripte#
Bisher haben wir lediglich in der REPL geübt und Eingaben getätigt.
Als Wiederholung der Inhalte schreiben wir die Befehle nun in ein Python-Dokument mit der Dateiendung .py (ein Script).
Dies ermöglicht eine übersichtlichere Darstellung dessen, was passiert und lässt uns die Eingaben in einem Dokument speichern.
Generell wird Code in einem Script von oben nach unten und von links nach rechts Zeile für Zeile verarbeitet. Ausnahmen bilden hier den Kontrollfluss beeinflussende Strukturen, die wir im weiteren Verlauf kennenlernen werden.
Wiederholung:
# Beispiel Python-Code
x = 5 + 3 # Zuerst wird 5 + 3 berechnet, dann wird das Ergebnis x zugewiesen
print(x) # Der Wert von x wird dann ausgegeben
Hier wird in der ersten Zeile der Variable ‘x’ der Wert von ‘5 + 3’ zugewiesen. In der zweiten Zeile wird dann der Wert von ‘x’ ausgegeben.
Aufgabe
Bearbeiten Sie diese Aufgaben wieder zusammen mit Ihrer Gruppe und diskutieren Sie die einzelnen Ausgaben gemeinsam. Schreiben Sie dann Ihr finales Ergebnis der Aufgabe 2 als Gruppe in das allgemeine Markdown padlet. Achten Sie auf ordentliche Darstellung und Formatierung. Geben Sie Ihrer Gruppe zudem noch einen Namen.
Öffnen Sie hierzu nun eine IDE, z.B. Pycharm oder VS Code. Im unteren Teil kann die schon bekannte REPL angezeigt werden. Das große, obere Fenster ist üblicherweise ein neues Python-Dokument in dem Sie - wie in der REPL - Einträge schreiben können. Jeder Befehl, Ausdruck oder Anweisung sollte dazu jeweils ohne Einrückung (für den Moment) in eine neue Zeile geschrieben werden.
Schreiben Sie mit Hilfe der
print()Funktion Ihr erstes Hello, World!-Programm. Speichern Sie es ab (Strg + s) und führen Sie es aus (Grüner Play-Button).Im Folgenden berechnen Sie die Fläche eines Rechtecks in Quadratkilometern mit Seitenlängen
a = 1,45 Meilenundb = 5,89 Meilen. Nutzen Sie Variablen für die Berechnung und geben Sie das Ergebnis in Quadratkilometern aus. Tipp: 1 Meile = 1.609 km.Starten Sie indem Sie zunächst die entsprechenden Variablen initialisieren. Denken Sie daran, welchen Datentyp Sie dafür nutzen und dass ein Punkt (.) als Dezimalseperator genutzt wird.
Konvertieren Sie dann die Werte zunächst zu Kilometern, berechnen anschließend die Gesamtfläche und geben diese dann aus.
Schreiben Sie Ihr Ergebnis in das geteilte Markdown-Dokument.
Lösung
# Erste Aufgabe:
print("Hello, World!")
# Zweite Aufgabe
# Variablen für die Seitenlängen des Rechtecks in Meilen initialisieren
a_meilen = 1.45
b_meilen = 5.89
# Konvertierung von Meilen zu Kilometern
a_kilometer = a_meilen * 1.609
b_kilometer = b_meilen * 1.609
# Berechnung der Gesamtfläche in Quadratkilometern
flaeche_quadkilometer = a_kilometer * b_kilometer
# Ergebnis ausgeben
print("Das Areal des Rechtecks beträgt", flaeche_quadkilometer, "Quadratkilometer.")
Kontrollstrukturen#
Algorithmen, und somit Pogrammierung, sind im Kern lediglich eine sehr ausführliche und komplexe Verkettung von wenn …, dann …*-Abläufen. Der Basistyp dieser Abfrage ist die if-else-Struktur in Python.
Als Beispiel betrachten wir einen Wasserkocher in Pseudocode:
Wenn die Wassertemperatur unterhalb der maximalen Wassertemperatur liegt:
dann erhitze das Wasser weiter.
Wenn die Wassertemperatur 100°C erreicht hat:
dann schalte den Wasserkocher aus.
in Python würde das in etwa so aussehen:
wassertemperatur = 36 # Es sind 36°C. Variablen haben keine "Einheiten".
wassertemperatur_max = 100
if wassertemperatur < wassertemperatur_max:
# Wenn die Wassertemperatur unterhalb der maximalen Wassertemperatur liegt, dann koche das Wasser.
kochen()
else:
# Andernfalls hat die Wassertemperatur die maximale Wassertemperatur erreicht oder überschritten.
# Dann stoppe den Kochvorgang.
ausschalten()
```{admonition} kochen() und ausschalten()
:class: dropdown
kochen() und ausschalten() sind hier erst mal Platzhalter für Code, der die entsprechende Funktionalität abbildet.
Die Klammern () kennzeichnen Aufrufe von Funktionen.
Funktionen bündeln eine Aufgabe und ermöglichen es, diese durch einen solchen Aufruf wieder zu verwenden.
Mehr dazu später - für den Moment konzentrieren wir uns auf die Kontrollstrukturen.*
### Das Konzept der Einrückung (Indentation)
Einrückung (Indentation) ist ein wichtiger Bestandteil der Python-Syntax und hat eine besondere Bedeutung für die Strukturierung von Python-Code.
Im Gegensatz zu anderen Programmiersprachen, die Klammern oder Schlüsselwörter wie "begin" und "end" verwenden, um Blöcke von Code zu kennzeichnen, verwendet Python Einrückung, um die Struktur und Hierarchie des Codes darzustellen.
Das Prinzip der Einrückung in Python ist einfach: Codeblöcke werden durch Einrückungen voneinander getrennt. Dies bedeutet, dass zusammengehörige Anweisungen, die innerhalb einer Funktion, einer Schleife oder einer Bedingung ausgeführt werden sollen, auf derselben Einrückungsebene stehen müssen.
Am obigen Beispiel des Wasserkochers kann dieses Prinzip verdeutlicht werden:
```python
wassertemperatur = 36
wassertemperatur_max = 100
if wassertemperatur < wassertemperatur_max:
kochen()
print('Wasser muss noch kochen')
else:
ausschalten()
print('Wasser ist heiß.')
In diesem Beispiel sehen Sie, dass der Code-Block, der nach der Bedingung wassertemperatur < wassertemperatur_max ausgeführt werden soll, um 4 Leerzeichen eingerückt ist.
Alle Anweisungen innerhalb dieses Blocks gehören zur Bedingung if.
Gleichzeitig gibt es einen else-Block, der ebenfalls um 4 Leerzeichen eingerückt ist.
Die Einrückung zeigt also, welcher Code innerhalb welcher Bedingung oder Schleife ausgeführt werden soll.
Diese Einrückung muss konsistent sein! Das bedeutet, dass alle Anweisungen auf derselben Einrückungsebene stehen müssen, um zusammengehörige Blöcke zu bilden. Andernfalls wird ein IndentationError ausgegeben.
Die Einrückung macht den Code lesbarer und fördert eine klare Strukturierung des Codes. Es ist daher wichtig, sich frühzeitig mit diesem Konzept vertraut zu machen, um sauberen und gut lesbaren Python-Code zu schreiben.
Bonusinhalt: Einrücken mit 4 Leerzeichen
Grundsätzlich kann jede konsistente Einrückung verwendet werden - Tabs, beliebig viele Spaces etc. Man hat sich jedoch in der Python-Welt darauf geeinigt, mit 4 Spaces zu arbeiten.
If-Else Ausdrücke#
Obiger Code stellt einen einfachen wenn, dann-Ausdruck dar.
Diese if-else-Ausdrücke sind eine Möglichkeit in der Programmierung, wenn, dann-Entscheidungen zu treffen, basierend auf bestimmten Bedingungen.
In unserem Wasserkocher-Beispiel wird somit erst überprüft ob die aktuelle Wassertemperatur unter der gewollten Maximaltemperatur liegt (Bedingung).
Wenn wenn das der Fall ist, wird weiter gekocht. Wenn die Bedingung nicht erfüllt ist (Wasser kocht schon), wird der Kochvorgang gestoppt.
Formalisiert kann diese Kontrollstruktur so dargestellt werden:
if condition:
# Führt diesen Code aus, wenn die Bedingung erfüllt ist
else:
# Führt diesen Code aus, wenn die Bedingung nicht erfüllt ist
Hierbei ist die Bedingung selbst oder dessen Ergebnis immer vom Datentyp Boolean!
Im oberen Beispiel wird ein Vergleichsoperator genutzt, um zwei Integer oder Floats miteinander zu vergleichen.
Das Ergebnis eines solchen Vergleiches ist immer ein bool’scher Ausdruck (True oder False).
Wenn die Abfrage komplexer wird, können auch mehrere Bedingungen in einem Ausdruck verkettet und überprüft werden.
Wichtig ist dabei jedoch, dass jede einzelne Bedingung wieder ein bool’scher Ausdruck sein muss:
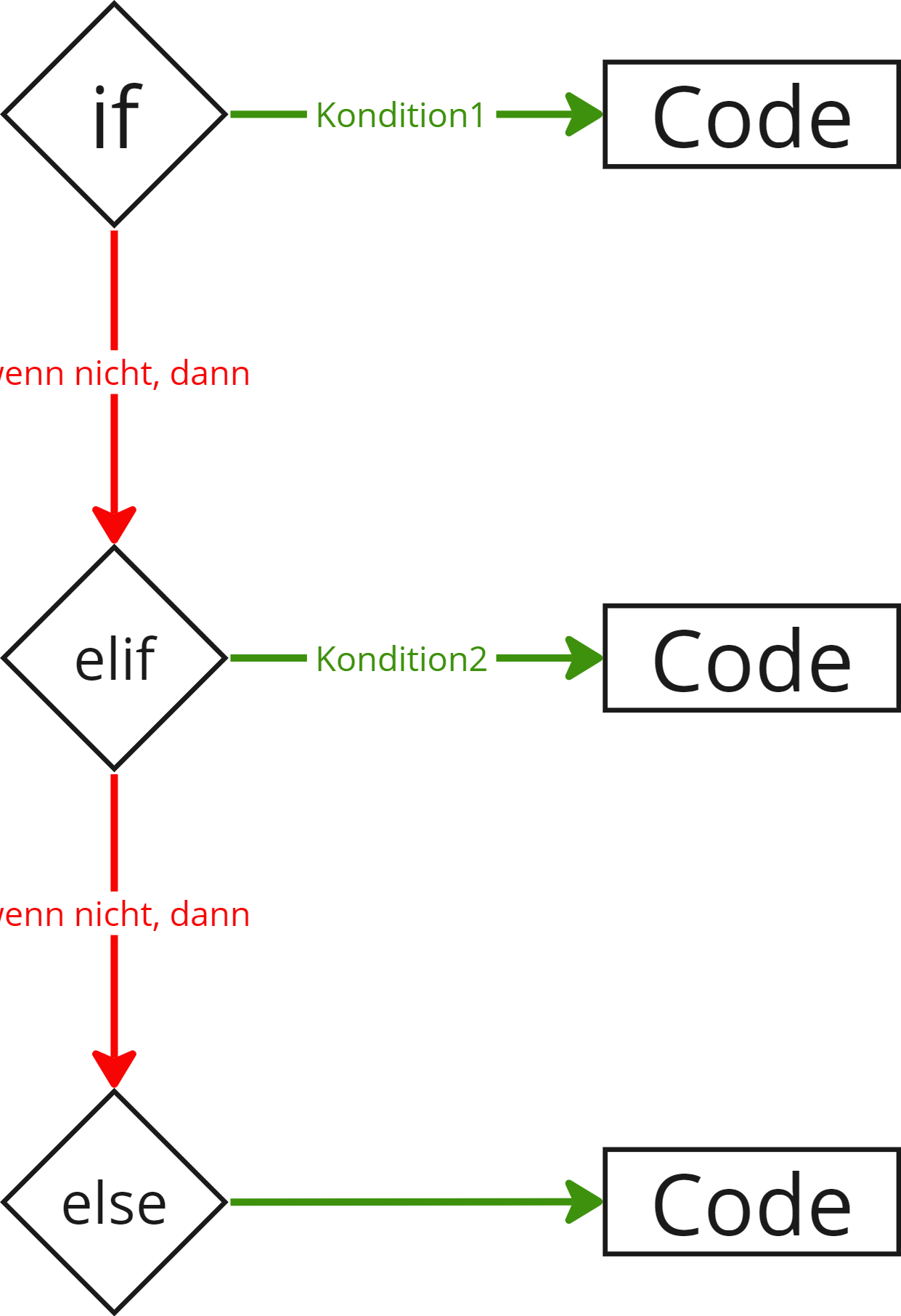
if condition1:
# Führt diesen Code aus, wenn die Bedingung condition1 erfüllt ist
elif condition2:
# Führt diesen Code aus, wenn die Bedingung condition1 nicht erfüllt ist, Bedingung condition2 aber schon
else:
# Führt diesen Code aus, wenn die Bedingungen condition1 und condition2 nicht erfüllt sind
Schematisch kann das folgendermaßen dargestellt werden:
Aufgabe
Bearbeiten Sie diese Aufgaben zusammen mit Ihrer Gruppe und diskutieren Sie die einzelnen Ausgaben gemeinsam. Schreiben Sie dann Ihre Erkenntnisse als Gruppe in das allgemeine Markdown padlet. Achten Sie auf ordentliche Darstellung und Formatierung. Geben Sie Ihrer Gruppe zudem noch einen Namen.
Schauen Sie auf folgende drei Beispiele. Welche Ausgabe erwarten Sie? Kopieren sie den Code in Ihre Entwicklungsumgebung und führen Sie ihn aus um Ihre Vermutung zu überprüfen.
Beispiel 1:
punktzahl = 85
if punktzahl >= 90:
print("Note A")
elif punktzahl >= 80:
print("Note B")
elif punktzahl >= 70:
print("Note C")
elif punktzahl >= 60:
print("Note D")
else:
print("Note F")
Beispiel 2:
monat = "Dezember"
if monat in ["Januar", "Februar", "Dezember"]:
print("Winter")
elif monat in ["März", "April", "Mai"]:
print("Frühling")
elif monat in ["Juni", "Juli", "August"]:
print("Sommer")
else:
print("Herbst")
Beispiel 3:
alter = 25
if alter < 12:
print("Ticketpreis: 5 €")
elif 12 <= alter <= 18:
print("Ticketpreis: 8 €")
elif 18 < alter <= 60:
print("Ticketpreis: 12 €")
else:
print("Ticketpreis: 6 €")
Schreiben Sie einen kleinen Test, ob Ihre Nutzer guten Geschmack haben, sprich welchen Schokoriegel (Mars, Bounty, Snickers, Twixx, Milky Way) sie bevorzugen. Speichern sie dafür eine simulierte Nutzereingabe in einer einfachen Variable. Prüfen Sie dann in einer
if-elif-else-Abfrage, welcher Schokoriegel bevorzugt wird. Geben Sie abhängig davon eine Meinung aus.
Schleifen#
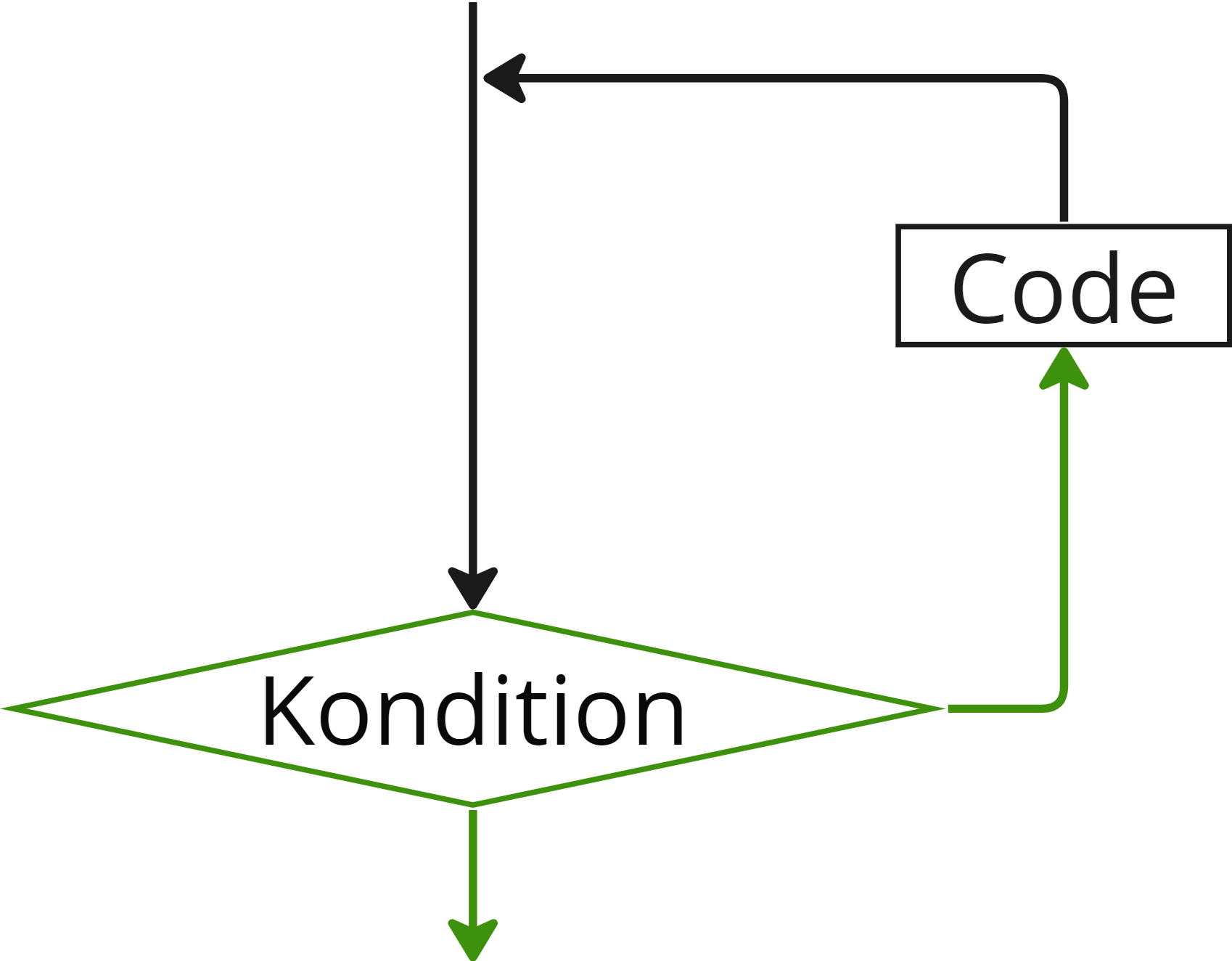
Nehmen wir wieder das Wasserkocher-Beispiel der vorherigen Aufgabe. Ein Wasserkocher sollte die Wassertemperatur nicht nur einmal überprüfen, sondern dies in regelmäßigen Abständen wieder tun. Eine Lösung wäre natürlich, viele dieser Abfragen nacheinander zu kopieren und diesen Code von oben nach unten, wie gewohnt, durchlaufen zu lassen. Dies wäre natürlich nicht nur ziemlich redundant und wiederholend, sondern auch unübersichtlich und fehleranfällig. Um dieses Problem zu lösen, gibt es sogenannte Schleifen oder auch loops genannt.
Generell ist eine Schleife in der Programmierung ein Vorgang, bei dem eine oder mehrere Anweisungen wiederholt ausgeführt werden, solange eine bestimmte Bedingung erfüllt ist. Das hilft, Aufgaben zu automatisieren und wiederholte Abläufe zu steuern. Im Beispiel wäre das im Pseudocode:
Während das Wasser noch nicht kocht:
kochen()
In Python sähe das wie folgt aus:
while wassertemperatur < wassertemperatur_max:
kochen()
Die obige Schleife würde somit so lange laufen bis die Wassertemperatur den Maximalwert erreicht.
Wichtig ist hierbei, dass zwingend darauf geachtet wird, dass die Schleifen-Bedingung logisch im Rahmen der Schleife erreicht werden kann.
Am Beispiel heißt das, dass die Wassertemperatur auch in jedem Durchlauf erhöht werden sollte.
Wenn dies nicht geschieht, wird die Wassertemperatur nie den Maximalwert erreichen. Die Schleife würde somit unendlich laufen, da die Kondition nie False ergeben würde und somit nie erfüllt wäre.
while wassertemperatur < wassertemperatur_max:
# kochen() passiert wie folgt:
wassertemperatur = wassertemperatur + 10 # fiktive Annahme
print(f'Wassertemperatur liegt gerade bei {wassertemperatur}°C')
In dieser Version wird die Wassertemperatur als bei jeder Iteration (Schleifendurchlauf) um 10 Kelvin erhöht. Hierdurch wird gewährleistet, dass die Kondition der Schleife erreicht werden kann und somit nicht unendlich fortgesetzt wird. Weiter wird die Wassertemperatur in jedem Durchgang mittels des print()-Statements ausgegeben.
Wir können also konstant überprüfen, wie weit wir gerade sind.
Bonusinhalt: f-Strings
Informieren Sie sich über f-strings für die Formatierung von Ausgaben.
Schematische Darstellung einer Schleife.
For-Schleife#
Anders als eine while-Schleife, die den Code so lange ausführt, bis eine bestimmte Bedingung erreicht ist, ist eine for-Schleife in der Programmierung eine Möglichkeit, eine Gruppe von Anweisungen für jedes Element in einer Sequenz auszuführen. Eine Sequenz kann eine Liste, ein Tupel, ein String oder eine andere Datenstruktur sein. In den folgenden Beispielen nutzen wir dafür range(start, end), was einer Folge von Ganzzahlen i mit start ≤ i < end entspricht.
Nehmen wir das Beispiel des kochenden Wassers wieder auf. Das ist jetzt mittlerweile zwar fast verkocht, für eine Tasse Tee reicht es aber noch. Dieser Tee soll natürlich nicht mehr gekocht werden sondern für 6 Minuten ziehen. Nehmen wir dafür nun an, dass wir sehr ungeduldig sind und jede Minute eine Rückmeldung brauchen, wie lange wir denn noch warten müssen.
Pseudocode:
Warte für insgesamt 6 Minuten:
gib jede Minute eine Rückmeldung wie lange noch zu warten ist
Python:
import time # import des Modules time
ziehzeit = 6 # Ziehzeit in Minuten
for minute in range(0, ziehzeit):
print(f'Es müssen noch {ziehzeit - minute} Minuten gewartet werden') # gibt aus, wieviele Restminuten noch zu warten sind
time.sleep(60) # nutzt die Funktion 'sleep' des Modules 'time' um den Code 60 Sekunden warten zu lassen
print('Geschafft! Der Tee ist nun fertig gezogen.')
In diesem Beispiel verwenden wir eine for-Schleife, um den Ziehvorgang für 6 Minuten zu wiederholen.
Die range(0, ziehzeit)-Funktion erzeugt die Sequenz von Zahlen von 0 bis 5 (einschließlich), die in jeder Iteration (Wiederholung) der Schleife verwendet wird.
Das heißt, die Schleife wird sechsmal durchlaufen, wobei minute jedes Mal den Wert der nächsten Zahl von 0 bis 5 annimmt.
Innerhalb der Schleife wird die verbleibende Wartezeit in Minuten ausgegeben und anschließend eine Minute gewartet.
Nachdem die Schleife beendet ist, wird die Nachricht Geschafft! Der Tee ist nun fertig gezogen. angezeigt.
Auf diese Weise können for-Schleifen verwendet werden, um Aktionen für jedes Element in einer Sequenz auszuführen.
Das ist besonders nützlich ist, wenn Sie eine bestimmte Anzahl von Wiederholungen benötigen, wie im Beispiel des kochenden Wassers.
Es wird um so sinnvoller, wenn die Sequenz nicht nur eine Sequenz von Zahlen ist, sondern eine Sequenz von unterschiedlichen Elementen.
Die Datentypen, die dafür verwendet werden können, behandeln wir im kommenden Kapitel.
Bonusinhalt: break, continue und pass
Um Kontrollstrukturen und somit den Programmfluss in Schleifen oder if-else-Blöcke weiter steuern zu können gibt es noch folgende Schlüsselwörter:
break: Beendet die Schleife vorzeitig, wenn eine bestimmte Bedingung erfüllt ist, und führt den Code nach der Schleife aus.continue: Überspringt den Rest der aktuellen Iteration in einer Schleife und fährt mit der nächsten Iteration fort.pass: Dient als Platzhalter und führt keine Aktion aus. Wird verwendet, wenn syntaktisch eine Anweisung benötigt wird, aber kein Code ausgeführt werden soll.
Diese Schlüsselwörter sind nützlich, um die Kontrolle innerhalb von Schleifen oder Bedingungen zu steuern und den Programmfluss so zu beeinflussen.
Weitere Beispiele
for i in range(1,10):
print(i)
for x in range(1,10):
print(x**2)
for k in range (10,100,10): # Was macht das dritte Argument?
print(f'{k} zum Quadrat: {k**2}')
Aufgabe
Schreiben Sie eine kurze Implementation von FizzBuzz. Das Programm soll
alle Zahlen von 1 bis 100 ausgeben,
wobeialle Zahlen, die durch 3 teilbar sind, durch
Fizz
undalle Zahlen, die durch 5 teilbar sind, durch
Buzz
undZahlen die durch 3 und 5 teilbar sind, sogar durch
FizzBuzz
ersetzt werden.
Versuchen Sie nun, den Code so kurz wie möglich zu machen.
Komplexe Datentypen#
Sie haben bisher schon unbewusst mit einem komplexeren Datentyp gearbeitet: Ein String ist auch eine Verkettung einzelner Buchstaben (sog. characters). Er unterstützt den Zugriff auf einzelne Elemente, wobei ein Buchstabe ein Element darstellt. Datentypen, die einen solchen Zugriff erlauben unterstützen die Indexierung und sind somit subscriptable. Einen solchen Zugriff auf einzelne Elemente in einem String kann mit eckigen Klammern durchgeführt werden. Wichtig: der Index, also die fortlaufende Nummer für die einzelnen Elemente beginnt bei ‘0’ und nicht bei ‘1’!
Bonusinhalt: Starten bei 0
Der Informatiker Edger W. Dijkstra hat hierzu eine fantastische Abhandlung geschrieben: https://www.cs.utexas.edu/~EWD/transcriptions/EWD08xx/EWD831.html
Beispiel:
+---+---+---+---+---+---+
| P | y | t | h | o | n | # Wert des Strings
+---+---+---+---+---+---+
0 1 2 3 4 5 # Index (startet bei 0!)
-6 -5 -4 -3 -2 -1 # negativer Index
also:
s = 'Python'
s[0] # Ausgabe 'P'
s[1] # Ausgabe 'y'
s[-1] # Ausgabe 'n'
s[3] # Ausgabe?
Bonusinhalt: Slicing
Teile eines sequenziellen Datentypens, wie dem eines Strings, können durch so genanntes Slicing ausgewählt werden. Hierfür muss ein Bereich von Indizes angegeben werden, der extrahiert werden soll. Generell ist die Syntax hierfür folgende:
Die allgemeine Syntax für das Slicing eines Strings lautet: string[start:stop:step].
start ist der Index, an dem das Slicing beginnen soll (einschließlich).
stop ist der Index, an dem das Slicing enden soll (ausschließlich).
step ist der Schritt, mit dem durch den String iteriert wird (optional).
Somit wäre im oberen Beispiel s[0:2] -> ‘Py’ oder s[0:5:2] -> ‘Pto’ Aufgabe:
- s[2:5:3] -> ?
- s[0:42:1] -> ? # Tipp: gentle slicing
- s[-3:-1] -> ?
- s[3] = 't' -> ? # Tipp: siehe Exkurs Mutability
Wer noch mehr Auwahl bzgl. des Extrahierens von Daten haben möchte, kann sich mit Regex-Ausdrücken beschäftigen. Sehr mächtiges Werkzeug, jedoch auch eine eigene Welt für sich.
Bonusinhalt: Mutability und wie Daten abgerufen werden
Mutability: mutable types: Werte können verändert werden (e.g. Listen, Dicts)
immutable Datentypen: Werte sind unveränderbar wenn die Identität (check via id(x)) gleich bleibt. Bspw. simple Datentypen und e.g. tuples.
Point the finger to the moon
Generell: Wie Variablen weitergegeben werden
Call-by-value -> nur der Wert wird weitergegeben
Call-by-reference -> der Speicherort der Variable wird weitergegeben
Call-by-object(-reference) in Python -> call-by-value für immutable Datentypen -> call-by-reference für mutable Datentypen
Das Slicing von subscriptable Strings ist eine leistungsstarke Technik in Python, die es ermöglicht, spezifische Teile eines Strings zu extrahieren, was besonders nützlich ist, wenn man mit Textdaten arbeitet.
Listen#
Eine Liste in Python ist eine geordnete Sammlung von Elementen, die in eckigen Klammern ([]) eingeschlossen sind und durch Kommas getrennt werden.
Listen können Elemente unterschiedlicher Datentypen enthalten, einschließlich anderer Listen und komplexer Datentypen wie Dictionaries und können verändert werden.
Es können Elemente hinzugefügt, entfernt oder geändert werden. Listen folgen dem Prinzip des Call-by-Reference und sind mutable.
kontinente = ["Afrika", "Antarktika", "Asien", "Europa", "Nordamerika", "Ozeanien", "Südamerika"]>
In diesem Beispiel ist kontinente eine Liste der Kontinente und jeder Kontinent ist ein Element der Liste. Der Datentyp list unterstützt auch die Indexierung und ist somit subscriptable - wie Strings (siehe oben). Der Index des ersten Elementes (hier: "Afrika"’) ist 0, der Index des zweiten Elementes 1 und so weiter.
Negative Indizes sind auch hier möglich.
Beispiel:
print(kontinente[0]) # gibt das erste Element aus: Afrika
print(kontinente[1]) # gibt das zweite Element aus: Antarktika
print(kontinente[2]) # gibt das dritte Element aus: Asien
# usw.
Iteration über Listen#
Wie oben im Kapitel ‘Schleifen’ schon angesprochen, kann mit der for-Schleife auch über Listen iteriert werden.
Dies kann dazu genutzt werden, die Elemente der Liste nacheinander auszugeben:
for element in kontinente:
print('---')
print(element)
Dies gibt der Reihe nach die Namen der Kontinente aus.
Bonusinhalt: Weitere Listenoperationen
Sie können auch auf Listenoperationen wie das Hinzufügen von Elementen mittels append(), das Entfernen von Elementen mittels remove() (wertbasiert) oder pop() (indexbasiert) und das Sortieren der Liste mittels sort() zugreifen.
Angenommen Sie haben eine Liste aller Planeten in unserem Sonnensystem
planeten = ["Merkur", "Venus", "Erde", "Mars", "Jupiter", "Saturn", "Uranus", "Neptun"]
Nun möchten Sie Pluto hinzufügen, da Sie der Meinung sind, dass dieser auch dazugehören sollte.
Das können Sie bspw. mittels append() machen. Dies fügt ein Element am Ende der Liste ein.
planeten.append('Pluto')
Nun diskutieren Sie mit Ihren Kommilitonen und sehen ein, dass das nicht ganz so gut war.
Ihnen bleiben jetzt zwei Möglichkeiten den Zwergplaneten wieder auszuradieren.
Zum einen kennen Sie den Namen als auch dessen Position in der Liste, da append() neue Elemente standardmäßig immer ans Ende der Liste anfügt.
Somit können Sie remove() oder pop() nutzen:
planeten.pop(-1)
# oder
planeten.remove('Pluto') # würde hier jetzt einen Fehler werfen - warum?
Außerdem gefällt Ihnen die Reihenfolge nicht. Diese können sie mit sort() verändern - Sie hätten das gern alphabetisch.
planeten.sort()
Top! Jetzt wäre alles geklärt.
Bonusinhalt: List comprehensions
List Comprehensions sind eine elegante und kompakte Möglichkeit, Listen in Python zu erstellen. Sie ermöglichen es, Listen auf eine einzige Zeile Code zu erzeugen, ohne dass Schleifen verwendet werden müssen. Das grundlegende Format einer List Comprehension lautet:
neue_liste = [ausdruck for element in liste]
Hier ist eine kurze Erklärung der einzelnen Teile:
ausdruck: Der Ausdruck, der für jedes Element in der ursprünglichen Liste angewendet wird, um die Elemente der neuen Liste zu erzeugen.element: Die Variable, die jedes Element der ursprünglichen Liste repräsentiert.liste: Die ursprüngliche Liste, über die iteriert wird.
# Beispiel 1:
quadrate = [x**2 for x in range(1, 6)]
# Beispiel 2:
kontinente_kurz = [landmasse for landmasse in kontinente if len(landmasse) <= 5] # Ausgabe: ['Asien']
Im ersten Beispiel wird eine Liste von Quadraten der Zahlen von 1 bis 5 erzeugt. Der Ausdruck x**2 wird für jedes Element x in der Range angewendet. Das Ergebnis ist die Liste [1, 4, 9, 16, 25].
Im zweiten Beispiel wird eine Liste erstellt indem über die Liste der Kontinente iteriert wird. Hierbei wird zudem noch eine Bedingung durch das if len(landmasse) <= 5 auf jedes Element angewendet. Die Funktion len() gibt die Länge des Strings zurück. Somit werden nur Elemente der Liste hinzugefügt, dessen Name kürzer oder gleich 5 Buchstaben ist.
Als normale for-Schleife sähe die Beispiele so aus:
# Beispiel 1:
quadrate = []
for x in range(1,6):
quadrate.append(x**2)
# Beispiel 2:
kontinente_kurz = []
for landmasse in kontinente:
if len(landmasse) <= 5:
kontinente_kurz.append(landmasse)
Nach erster Eingewöhnung sind List-Comprehensions nicht nur eine kompakte Möglichkeit Listen zu erstellen, sondern machen den Code auch oft lesbarer und einfacher zu verstehen.
Aufgabe
Legen Sie zuerst selbst eine Liste der Kontinente an.
Geben Sie nun alle Namen der Kontinente nacheinander aus
Sortieren Sie die Liste alphabetisch absteigend (von Z nach A).
Tipp
Schauen Sie in die Dokumentation für list.sort().
Gehen Sie nun die Liste Element für Element durch und geben Sie nur die Kontinente aus, die mit ‘A’ anfangen.
Schreiben Sie diese Kontinente in eine neue Liste.
Tipp
Tipp: Eine Liste muss leer vor der Schleife initialisiert werden
Geben Sie nun nur die Kontinente aus, die mit ‘amerika’ aufhören, und löschen Sie den Rest aus der Liste.
Tipp
Operator in und pop() oder remove()
Was kommt raus und woran liegt es?
kontinente = ['Afrika', 'Antarktika', 'Asien', 'Europa', 'Nordamerika', 'Ozeanien', 'Südamerika']
l = kontinente
l.pop(2)
l[3] = 'Eurasien'
print(kontinente) # Ausgabe?
Dictionaries#
Ein Dictionary in Python ist eine ungeordnete Sammlung von Elementen, die durch Schlüssel-Wert-Paare dargestellt werden.
Jedes Element in einem Dictionary besteht aus einem Schlüssel und dem zugehörigen Wert.
Dictionaries werden mit geschweiften Klammern ({}) definiert, wobei jedes Schlüssel-Wert-Paar durch einen Doppelpunkt (:) getrennt ist.
Die einzelnen Elemente eines dict, also die einzelnen Schlüssel-Wert-Paare, sind mit Komma getrennt (,).
ozeanien = {'flaeche': '9000000', 'laender': 14, 'einwohnerzahl': 45}
In diesem Beispiel ist ‘ozeanien’ ein dict, das (korrekte?) Informationen über den Kontinent Ozeanien enthält.
Der Schlüssel "flaeche" hat den Wert '9000000', der Schlüssel "laender" hat den Wert 14, und der Schlüssel "einwohnerzahl" hat den Wert 45.
Sie können auf den Wert eines bestimmten Schlüssels zugreifen, indem Sie den Schlüssel angeben.
print(f'Fläche: {ozeanien['flaeche']}')
print(f'Anzahl der Länder: {ozeanien['laender']}')
Formaler kann ein Dictionary so erstellt werden:
neues_dict = {'Schlüssel1': 'Wert1', 'Schlüssel2': 'Wert2', 'Schlüssel3': 'Wert3'}
In diesem Beispiel haben wir ein neues Dictionary neues_dict erstellt, das drei Schlüssel-Wert-Paare enthält:
'Schlüssel1' mit dem Wert 'Wert1', 'Schlüssel2' mit dem Wert 'Wert2' und 'Schlüssel3' mit dem Wert 'Wert3'.
Es können auch nacheinander Schlüssel und Werte hinzugefügt werden:
neues_leeres_dict = {}
neues_leeres_dict['Schlüssel1'] = 'Wert1'
neues_leeres_dict['Schlüssel2'] = 'Wert2'
neues_leeres_dict['Schlüssel3'] = 'Wert3'
oder aus einer Liste an Tupeln gelesen werden.:
tupel_liste = [('Schlüssel1', 'Wert1'), ('Schlüssel2', 'Wert2'), ('Schlüssel3', 'Wert3')]
neues_dict_aus_tupeln = dict(tupel_liste)
Der Zugriff auf die Werte wäre hier immer in der selben Art und Weise:
neues_dict['SchlüsselXY']
Wird auf diese Weise auf einen nicht vorhanden Schlüssel zugegriffen, so wird ein KeyError zurückgegeben.
Um sicherzugehen, dass ein Wert zurückgegeben wird, kann stattdessen die get()-Methode verwendet werden:
neues_dict.get('Nicht_Vorhandener_Schlüssel') # gibt None zurück
Falls der Schlüssel nicht vorhanden ist, kann stattdessen ein Standard-Wert übergeben werden, der dann zurückgegegeben wird.
neues_dict.get('Anderer_Schlüssel', 'Standard-Wert')
Es kann in einem Dictionary immer nur ein Wert pro Schlüssel hinzugefügt werden. Allerdings kann dieser Wert auch eine Liste oder ein Tupel sein, die dann wiederum mehr Elemente beinhalten.
mein_dict = {
'Schlüssel1': ['Wert1', 'Wert2'],
'Schlüssel2': ['Wert3', 'Wert4'],
'Schlüssel3': ['Wert5', 'Wert6']
}
In diesem Beispiel hat jeder Schlüssel in mein_dict eine Liste mit zwei Werten, die den Werten 'Wert1' und 'Wert2', 'Wert3' und 'Wert4', sowie 'Wert5' und 'Wert6' entsprechen.
Sie können dann auf diese Werte zugreifen, indem Sie den Schlüssel verwenden und dann den Index der Liste angeben. Zum Beispiel:
print(mein_dict['Schlüssel1'][0]) # Ausgabe: Wert1
print(mein_dict['Schlüssel1'][1]) # Ausgabe: Wert2
Sie können auch auf Dictionary-Methoden wie das Hinzufügen von Schlüssel-Wert-Paaren mittels update(), das Entfernen von Schlüssel-Wert-Paaren mittels pop() und das Abrufen aller Schlüssel oder Werte mittels keys() bzw. values() zugreifen.
Das Verständnis von list und dict ist entscheidend, da sie häufig in Python-Programmen verwendet werden, um Daten zu speichern, zu organisieren und zu verarbeiten.
Es ist vollkommen klar, dass Sie nach einer so kurzen Einführung noch viele offene Fragen haben - Fragen Sie gern und viel!
Letztlich ist es viel praktische Erfahrung durch Ausprobieren und Anwenden, was Ihnen den Umgang und das weitere Verständnis hiervon ermöglicht.
Weitere komplexe Datentypen#
Zur weiteren Übersicht hier noch die komplexen Datentypen Tupel, Set und Range. Diese werden wir in diesem Kurs nicht weiter behandeln. Ihr findet auch einen kurzen Kommentar zum Thema Array.
Tupel (Tuples):#
Ein Tupel ist ähnlich wie eine List, aber im Gegensatz zu Listen sind Tupel unveränderlich (immutable), d.h., nachdem sie erstellt wurden, können ihre Elemente nicht geändert werden. Tupel werden mit runden Klammern (()) definiert und können verschiedene Datentypen enthalten.
Beispiel:
punkt = (10, 20)
In diesem Beispiel ist punkt ein Tupel mit den Koordinaten (10, 20).
punkt[0] == 5
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
punkt[0] = 5
~~~~~^^^
TypeError: 'tuple' object does not support item assignment
Wäre punkt eine list, würde diese Änderung funktionieren - aber tuple unterstützt diese Operation nicht. Die list-Operationen add(), remove() oder ähnliche werden auch nicht unterstützt.
Mengen (Sets)#
Ein Set ist eine ungeordnete Sammlung von eindeutigen Elementen. Mengen sind nützlich, um Duplikate zu entfernen und Mengenoperationen wie Vereinigung, Schnitt und Differenz durchzuführen. Mengen werden in geschweiften Klammern ({}) definiert und Elemente werden durch Kommas getrennt.
Beispiel:
farben = {"rot", "grün", "blau"}
In diesem Beispiel ist farben eine Menge mit den Elementen "rot", "grün" und "blau". Beachten Sie, dass Mengen keine Duplikate enthalten können.
Range#
Range ist ein “Datentyp”, der eine Sequenz von Zahlen darstellt. Sie wird häufig in for-Schleifen verwendet, um eine bestimmte Anzahl von Iterationen durchzuführen. Eine Range wird mit der Funktion range() erstellt.
Beispiel:
zahlen = range(0, 6) # vgl. die Aufgabe der Ziehzeit des Tees
In diesem Beispiel ist zahlen eine Range von 0 bis 5 (einschließlich).
Arrays#
Einigen unter Ihnen mag der Datentyp Array bekannt sein, etwa aus Java. Dieser ist so in Python nicht standardmäßig implementiert, in Python ist ein vergleichbarer Datentyp mit list vorhanden.
Über das Modul NumPy kann der Datentyp numpy.ndarray verwendet werden, der leicht anders als list funktioniert - auf die Details einzugehen ginge aber über diesen Kurs hinaus.
Hands on#
Tüfteleien mit Listen und Dictionaries
Erstellen Sie eine Liste mit 5 verschiedenen Hauptstädten (Strings)
Erstellen Sie eine zweite Liste mit den 5 dazugehörigen Ländern (Strings)
Kombinieren Sie diese beiden Listen zu einer Liste und geben Sie die Anzahl der Elemente dieser aus.
Spielen Sie nun ein wenig mit der Liste. Was passiert wenn Sie die Liste mit 2 multiplizieren? Wie entnehmen Sie der Liste wieder Elemente und wie fügen Sie welche hinzu?
Weisen Sie die Liste nun einer anderen Variable zu. Entnehmen Sie anschließend dieser neuen Liste 2 Elemente. Wieviele Elemente hat die Liste dann noch? Vergleichen Sie es mit der ‘alten’ Liste. Was fällt auf? Was hätten Sie erwartet und woran liegt es?
Erstellen Sie nun ein Dictionary aus folgender Tabelle:
Land
Hauptstadt
Philippinen
Manila
Kirgistan
Bischkek
Fügen Sie nun zwei weitere Länder und entsprechende Hauptstädte hinzu.
Können Sie aus den oberen beiden Listen auch direkt ein Dictionary erstellen?
Tipp
Schauen Sie sich die Funktion
zip()an.Geben Sie nun die Länder mit ihren Hauptstädten einzeln aus.
Tipp
Arbeiten Sie mit den Funktionen
dict.keys(),dict.values()undlist().Erstellen Sie nun ein Dictionary, das als Schlüssel (
key) den Namen des Landes hat und je als Wert einelistaus dem Namen der entsprechenden Hauptstadt und dessen Koordinaten hat. Dasdictsollte bei einem Aufruf von bspw.laender_hauptstaedte["Philippinen"]eine Ausgabe von["Manila", (14.583333, 121.0)]ergeben. Achten Sie hier darauf, dass die Koordinaten nochmals als Tupel gespeichert worden.
Bonusinhalt: Aufgabe “for the fast ones only”
Sie werden am heutigen Abend eine Quizshow über die Zugehörigkeit von Hauptstädten zu Ländern in Europa halten. Da Sie als gute Geographiestudent:In keine Ahnung haben, welche Hauptstädte zu welchen Ländern gehören, wollen Sie diese Aufgabe nun automatisieren.
Zur Vereinfachung haben wir Ihnen die Daten schon zur Verfügung gestellt:
Datengrundlage Europa Länder und Hauptstädte
hauptstaedte = ['Andorra la Vella', 'Athen', 'Belgrad', 'Berlin', 'Bern', 'Bratislava', 'Brüssel', 'Budapest', 'Bukarest', 'Chișinău', 'Città di San Marino', 'Dublin', 'Helsinki', 'Kiew', 'Kopenhagen', 'Lissabon', 'Ljubljana', 'London', 'Luxemburg', 'Madrid', 'Minsk', 'Monaco', 'Moskau', 'Nikosia', 'Oslo', 'Paris', 'Podgorica', 'Prag', 'Reykjavík', 'Riga', 'Rom', 'Sarajevo', 'Skopje', 'Sofia', 'Stockholm', 'Tallinn', 'Tirana', 'Vaduz', 'Valletta', 'Vatikanstadt', 'Vilnius', 'Warschau', 'Wien', 'Zagreb']
laender = ['Andorra', 'Griechenland', 'Serbien', 'Deutschland', 'Schweiz', 'Slowakei', 'Belgien', 'Ungarn', 'Rumänien', 'Moldau', 'San Marino', 'Irland', 'Finnland', 'Ukraine', 'Dänemark', 'Portugal', 'Slowenien', 'Vereinigtes Königreich', 'Luxemburg', 'Spanien', 'Belarus', 'Monaco', 'Russland', 'Zypern', 'Norwegen', 'Frankreich', 'Montenegro', 'Tschechien', 'Island', 'Lettland', 'Italien', 'Bosnien und Herzegowina', 'Nordmazedonien', 'Bulgarien', 'Schweden', 'Estland', 'Albanien', 'Liechtenstein', 'Malta', 'Vatikanstadt', 'Litauen', 'Polen', 'Österreich', 'Kroatien']
Nicht-wissenschaftliche Quelle der Daten
Wichtig: Die Listen sind beide gleich geordnet. Das heißt, das Land mit Index 5 hat die Hauptstadt mit Index 5.
Fügen Sie die Listen der Länder und der Hauptstädte Ihrem Code hinzu.
Implementieren Sie nun ein Quiz. Dabei soll zunächst ein Land (oder eine Hauptstadt) ausgegeben werden. Die Nutzerin soll dann den anderen Teil, also die zugehörige Hauptstadt (oder das zugehörige Land) eingeben. Diese Eingabe soll dann gegen die in den Daten hinterlegte Lösung geprüft werden - und eine passende Erfolgs- oder Misserfolgs-Meldung ausgegeben werden.
Den zugehörige Input der Nutzerin können sie im Code “simulieren”. Wenn Sie mehr Interaktivität erreichen wollen, gucken Sie sich die Funktion
input()an.
Bonusinhalt: Datengrundlage - Wie komme ich da dran?
Code um die Daten aus Wikipedia runterzuladen und zu bereinigen: Notiz: Benötigt externe Module, Regex-Begriffe sowie Verständnis von Funktionen
import pandas as pd
import re
url = 'https://de.wikipedia.org/wiki/Liste_der_Hauptst%C3%A4dte_Europas'
tabellen = pd.read_html(url)
tabelle = tabellen[0]
laender = tabelle['Staat']
hauptstaedte = tabelle['Stadt']
# DataFrame erstellen
df = pd.DataFrame(tabelle, columns=['Stadt'])
# Funktion zum Bereinigen der Zeichenfolgen definieren
def bereinige_stadtname(name):
# Alle Zahlen und Klammern entfernen
bereinigter_name = re.sub(r'\d+', '', name) # Entfernt Zahlen
bereinigter_name = re.sub(r'\([^()]*\)', '', bereinigter_name) # Entfernt Klammern und ihren Inhalt
# Führende und nachfolgende Leerzeichen entfernen
bereinigter_name = bereinigter_name.strip()
return bereinigter_name
# Funktion auf die gesamte Spalte anwenden
df['Bereinigter Stadtname'] = df['Stadt'].apply(bereinige_stadtname) # wendet die Funktion auf den Dataframe an
hauptstaedte = df['Bereinigter Stadtname']
# Ergebnis anzeigen
print(hauptstaedte)